
Task Objective: Web Scraping
Build a scraping tool using WebScraper.io. Learn to construct, refine and compile digital datasets for real-world applications.
My Objective (Self-Initiated Work)
I intend to run a series of experiments targeting major UK streaming platforms, specifically BBC iPlayer and ITV, to better understand their underlying data structures. By creating different scrapers for these sites, I aim to curate diverse datasets, which will allow me to critically compare how these digital media giants organize and present their content.
What is web-scraping?
At its core, web scraping is about turning the chaotic, unstructured noise of the internet into clean, usable data. It’s the process of using code to automate the collection of information, and organizing it into a format we can actually analyse, like a spreadsheet or database. It lets us spot trends, track competitor movements, and understand digital patterns at a scale that would be impossible manually.
The foundational stages of web scraping are website analysis, crawling, and data organizing. This process should not be confused with data mining, which requires complex statistical methods for data analysis, while scraping focuses solely on data acquisition. Due to the abundance of efficient tools and libraries, web scraping is generally an easy process (Milev, 2017 ; Krotov and Silva, 2018, cited in, Khder, 2021).
Challenge: I found it difficult to determine the correct selector to retrieve the kind of data I wanted scraped. Also, I noticed that every website is different. Hence the scrapers used for the websites tend to be different even though it is to extract the same kind of data. I could not get my scraper to scrape images for me. It takes some level of trial and error to get the hang of using a web scraper tool.
Key Insight: Tools like WebScraper.io often underperform because "point and click" automation struggles with the web's inherent complexity, sometimes failing to access key data points or entire pages. This is understandable given that the web is an open, dynamic system where standards and technologies are constantly changing and inconsistently applied. The fluidity of web content, which is generated and modified quickly, means that even advanced visual scraping tools frequently need custom code to function correctly (Krotov et al., 2020).
It’s not the Wild West. Scraping comes with some heavy ethical and legal baggage. We have to constantly balance the technical ability to grab data with the moral responsibility of doing so legally and respectfully. The paradoxical nature of web data makes its legal and ethical retrieval complex. The web's design mandates public accessibility, an openness that benefits content providers by maximizing their user base. Yet, this same content is an essential asset that owners wish to safeguard, often aspiring to establish it as proprietary property. This aspiration faces a legal challenge, as website owners are not always considered the legal owners of the data generated by their users (Dryer and Stockton, 2013, cited in, Krotov et al., 2020).

Figure 1.1: A snapshot of my title scraper tool on Channel 4.
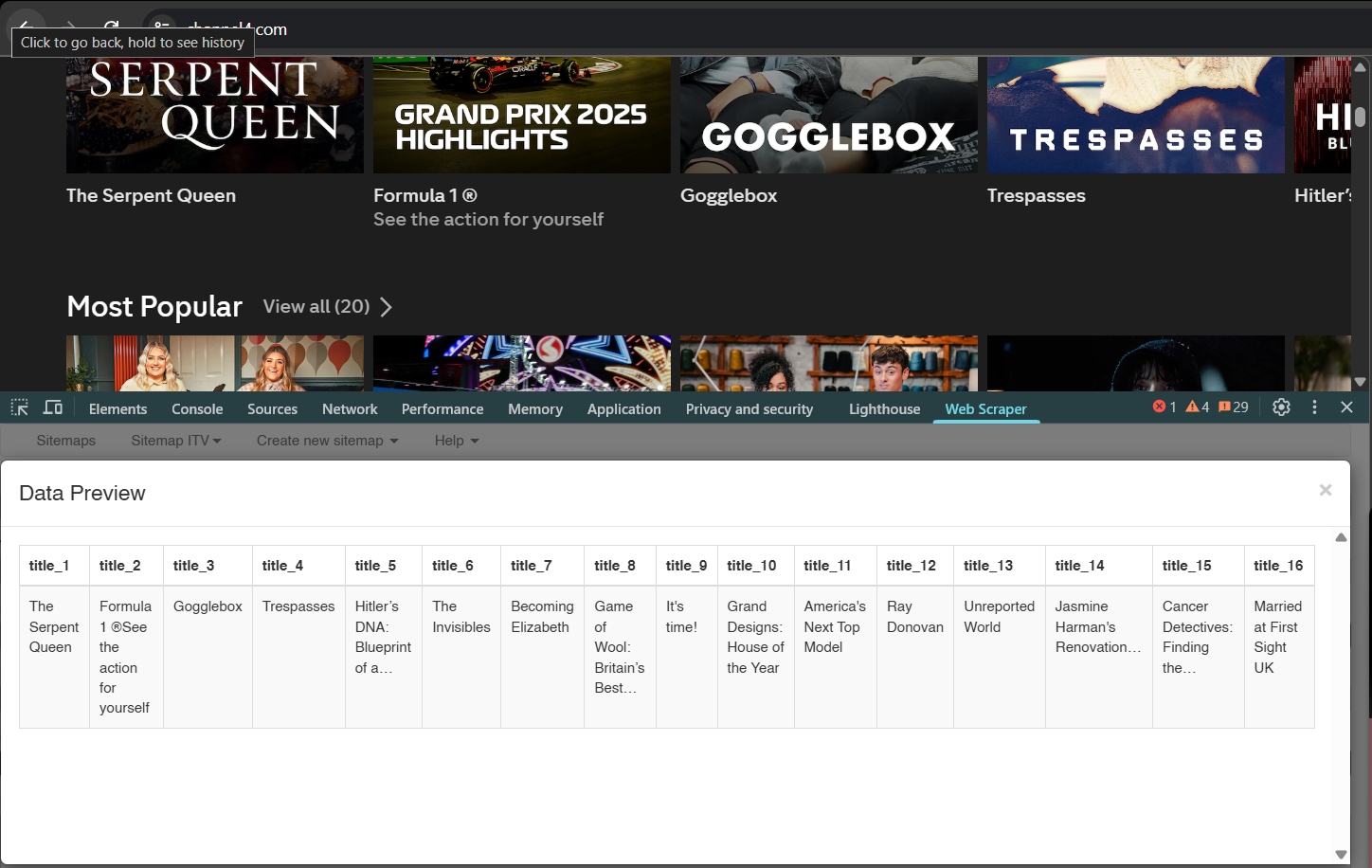
Figure 1.2: A snapshot of my scraped data from Channel 4 using the title scraper tool.
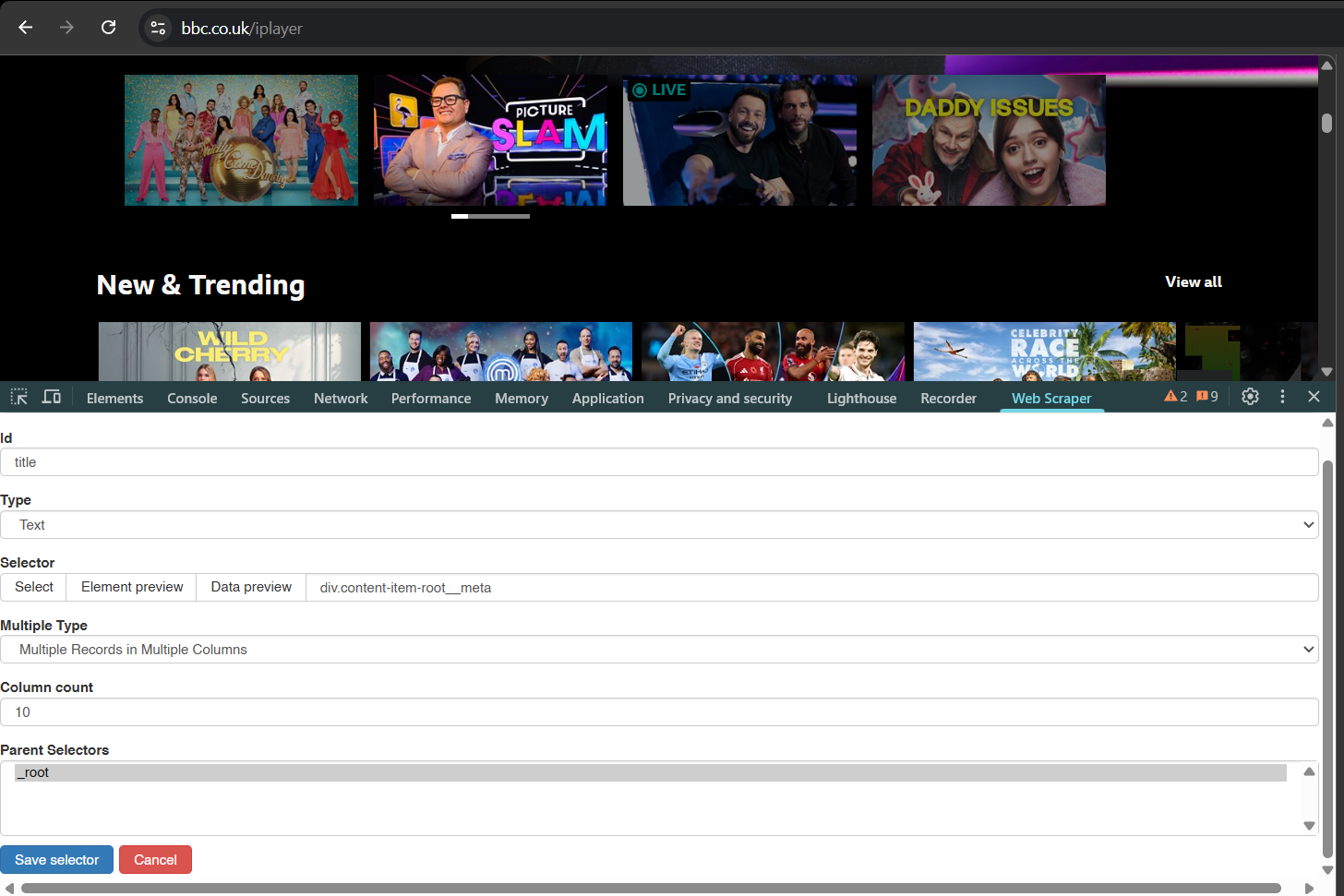
Figure 2.1: A snapshot of my title scraper tool on BBC Iplayer.
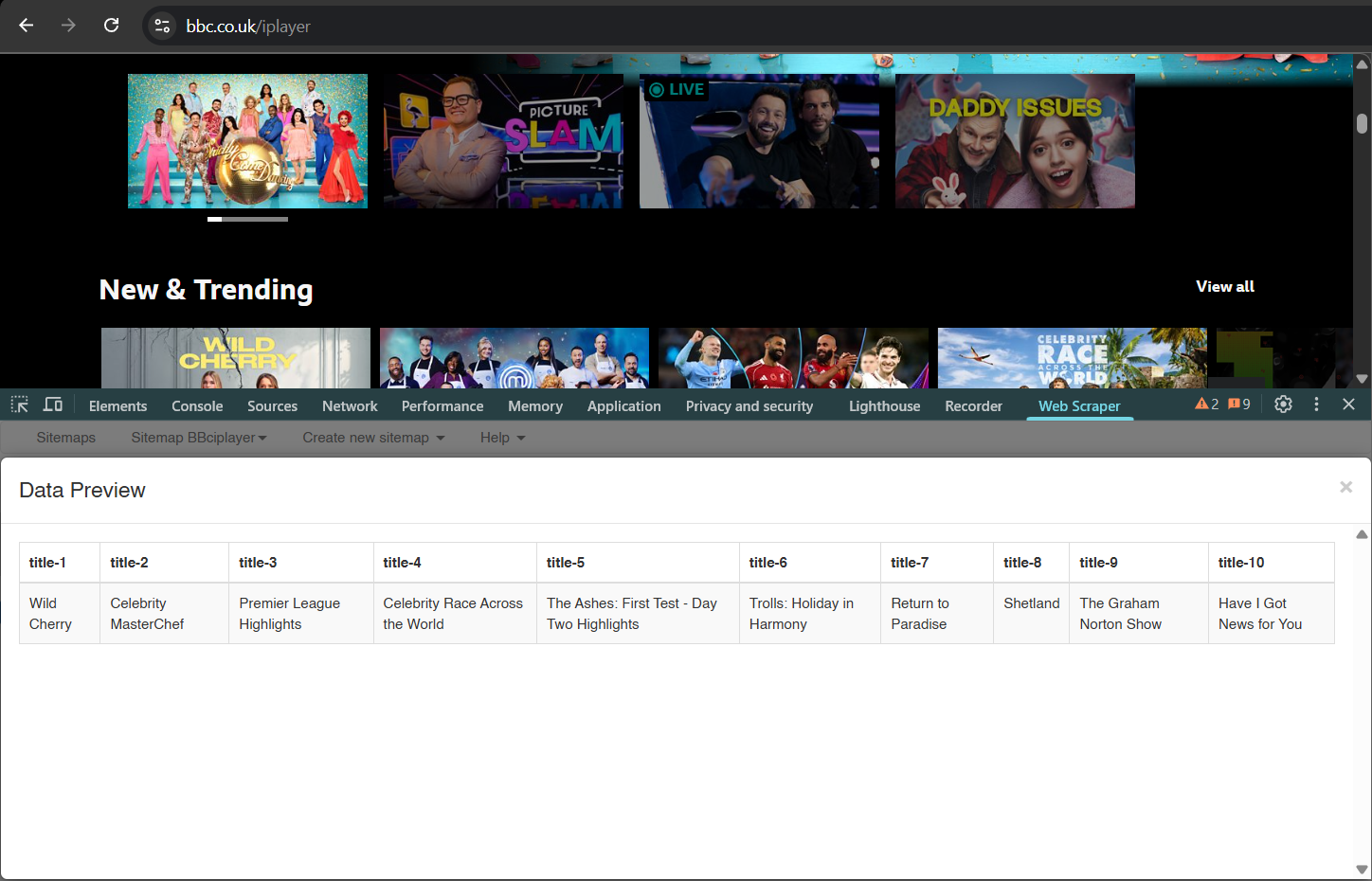
Figure 2.2: A snapshot of my scraped data from BBC Iplayer.
The Hidden Traps of 'Easy' Data
Data extracted from the internet might look clean on the surface, but it comes with some insidious validity issues that can mess up a collected dataset (Boegershausen et al., 2022).
- Websites change fast: If you don't capture the context of when and how the site looked at that exact moment, your data loses meaning.
- Algorithms are watching: E-commerce and media sites often personalize what they show you. My scrape of a site might look totally different from yours, which raises questions about objectivity. Does the website show me a neutral page or is it tailored according to my cookies and/or location?
- Keep the receipts: If you don't save the screenshots from the scraping process, you can't validate your findings later. It’s crucial to back up the source, not just the output (Ulloa et al., 2025).
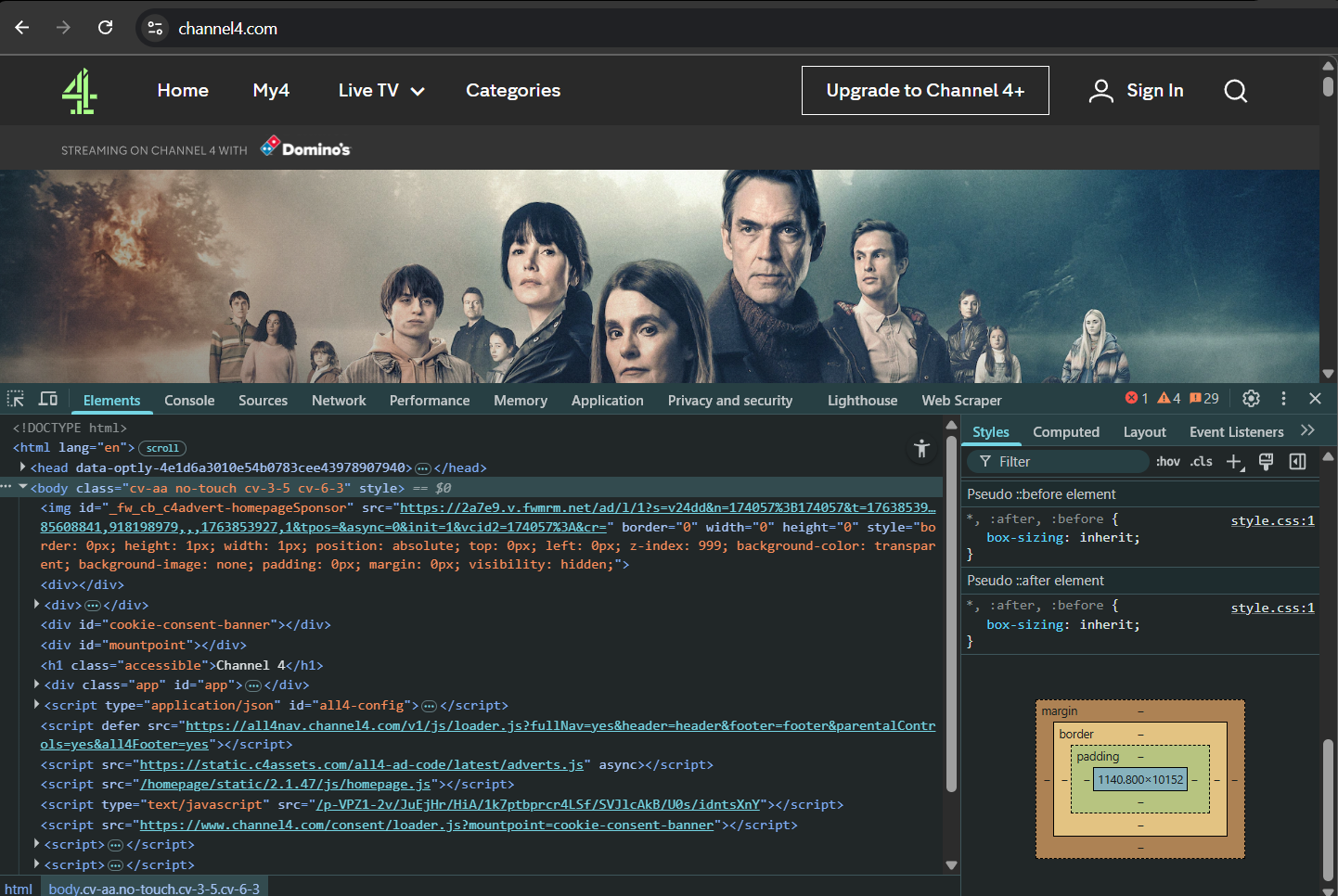
Figure 3: A snapshot of Channel 4's homepage elements via 'Inspect'.
References
- Boegershausen, J., Datta, H., Borah, A. and Stephen, A., T. 2022. Fields of Gold: Scraping Web Data for Marketing Insights. Journal of Marketing. 86(5), pp.1–20.
- Khder, M. 2021. Web Scraping or Web Crawling: State of Art, Techniques, Approaches and Application. International Journal of Advances in Soft Computing and its Applications. 13(3), pp.145–168.
- Krotov, V., Johnson, L. and Silva, L. 2020. Legality and Ethics of Web Scraping. Communications of the Association for Information Systems. 47, pp.555–581.
- Ulloa, R., Mangold, F., Schmidt, F., Gilsbach, J. and Stier, S. 2025. Beyond time delays: how web scraping distorts measures of online news consumption. Communication Methods & Measures. 19(3), pp.179–200.